There’s a lot of Murlocs ahead. Proceed at your own risk. I haven’t really fleshed out this section yet, so things are sporadic, and there is a lack of proper presentation in the rest of the chapter. However, it is possible to read on as I’m building the document. Just expect there to be a lot of hidden ponds of water, so bring your Iskaaran Raft if you go exploring. And harpoon those Murlocs.
—Mglrmglmglmgl.
Many of the stats-based WoW sites have a section of M+ compositions. The idea is to show which compositions are popular and to provide some inspiration on what compositions to form. Many considerations factor into a great composition. Not only do you want great damage, you also want to have the right kind of utility, and the right defensive options.
Furthermore, you want the group to be able to deal with all dungeons for a season, because this will keep the group stable.
Our approach provides a more data-analytic approach to the composition data. We are not that interested in the question of “what do people run?” because this is easily given by a lot of other sites. Rather, we are interested in finding the most influential decisions which goes into forming a group.
The real decision revolves around damage, defensives and utility. The data we have is what specs were selected. This makes the real reasons indirect: we have to look at spec selection, and then deduce the decisions based on those selections.
In practice, there may not be an obvious “best selection”, but rather a number of viable selections at the highest level. In a healthy meta, several options are possible, even at the highest level. If a few specs are must-bring, it can lead to a less healthy meta-game. The number of players in a M+ group is limited to 5, and you need 1 tank and 1 healer. So if a given class is more or less required, that takes up a valuable slot. Furthermore, the profile of the must-bring spec will dictate which specs goes well along it. In turn, it can lead to a more stale meta-game.
To tease out the possible selection clusters, we are going to rely on a mathematical workhorse from linear algebra: the singular value decomposition (SVD). The SVD allows us to decompose a table of specs from runs into a different view. In this new view, we have a different frame-of-refence, where the math points to the most influential selections. By analysing the new view, we gain insight in what is important to consider.
One thing to stress is that this analysis bases itself on what players are selecting to use for runs. That is, players are sort-of “voting” on compositions. It might very well be there are other viable compositions, but they aren’t chosen by some of the high-key-level groups. The composition is a puzzle to solve, and you can base the solution around an off-meta pick. However, the analysis of the most voted-on solutions will give us insight in what tends to be the the defining choices.
We proceed in two steps. First, we analyse tank/healer pairings through Correspondence Analysis (CA). While this analysis completely ignore DPS contributions, the mathematical model is simpler and provides more explanatory power. The second analysis uses Multiple Correspondence Analysis (MCA) to factor in the DPS players as well. However, MCA has less explanatory power than CA. Both methods have valuable input.
10.1 Low key level groups
For a group running at a lower key level, the compositional structure of the group matters a whole lot less. As long as you bring decent players, you will have a great time. All specs brings some kind of useful utility, and you have a great deal of flexibility in your choices. Gradually, as you increase the key level, the compositional structure will have more an more influence on the ease of running the key. Hence, people will still try to get some kind of coherent structure into the group.
A key point is that the best group varies with key level. It is not a priori a given you can transplant a high-performing composition at the top to the lower key levels and have it perform as well. Maybe the group itself is high-risk/high-reward because people are trying to push a high key, and some part of the dungeon requires you to play the high-risk team to get through. Another reason is that some specializations excel at certain key levels, and this can have a domino-effect on the group structure.
10.2 Theory
This section explains the general idea of how we are going to approach the compositional meta of M+ dungeon runs.
10.2.1 Naive approaches
You could count specializations and look at their popularity. The more common specs would be considered part of the meta. This is a great idea, but it fails to handle an important case: emergent effects. Some times, the power of a spec comes from a particular pairing with another spec. An example is that Mage often pairs well with Rogue. Likewise, Augmentation Evoker will have specs it prefers to run with over other specs.
This leads to the conclusion one has to consider multiple specializations at once.
Another approach would be to count full compositions. We simple count how many times a given composition occur. The problem here is that a group might have a flex-pick. Perhaps 4 of the specs in the group define the meta, and the final spec can be more or less whatever you like as long as it is a melee-spec. This dilutes the counts in a way which makes it hard to figure out what is really going on.
Hence we need an approach which can consider combinations of specializations, and we also need some efficiency because we can’t consider all of them. There’s quite a few, even if we rule out compositions with multiple copies of the same specialization:
# A tibble: 2 × 2
Kind Count
<chr> <dbl>
1 Dupes 738192
2 No Dupes 109200
10.2.2 Analysis of compositions
Suppose you are to form a 5-man M+ team. You are looking at the first pick, and you pick a Fire Mage. This pick informs the next picks you are about to make. Certain specs will get incited and become more likely to be picked. Other specs will become suppressed, and are less likely to be picked. Finally, some specs doesn’t change in likelihood of getting picked.
Suppose you were to form another team, and your first pick was a preservation evoker. The same thing might happen: some specs will be incited, and some will be supressed. But the extent to which the separation of specs happen might be much smaller on preservation evoker than in the example of a fire mage. That is, the pick of fire mage provides a lot of separation, whereas the pick of preservation evoker produces little separation.
Or said in another way: Fire Mage is less flexible and is more picky about what is likely to be chosen as sibling-specs. Preservation evoker is more flexible and can run with a large variety of other specializations.
From a compositional point of view, the example tells us something important. A specialization with lots of separation provides more information about the meta. Once you have a few specializations with high separation locked in, the rest of the group composition is more or less given. By analysing the compositions among the highest level players, we can compute how likely certain spec-combinations are. This gives us a likelihood of being picked, which is what we want in order to compute the seperation values of different specs.
Note that the absence of a certain spec is also information-carrying. If you happen to know that Fire Mage does not occur in a composition, it might make something like Balance Druid more likely to occur.
The next big idea is to look at combinations of specs. Rather than looking at Fire Mage in isolation, we might want to look at the pair of Fire Mage and Subtlety Rogue simultaneously. It might be that the pair provides a larger degree of separation than the individual parts.
This combination-idea is fundamental because it allows us to evaluate groups of picks at the same time. We get away from the naive approaches of looking at single specs and full compositions. And we get a way to deal with the enormous amount of combinations as we shall see.
Our goal is to figure out what combinations provide a lot of separation. Large seperation will provide a view which spreads out the compositions and points to clusters of specializations which go well together. Large separation will provide a lot of signal in the noise. Once we know which combinations are separating, we can perform a lossy compression on our information: remove all data which provides little separation, retaining the information with the most signal.
10.2.3 SVD
We’ll begin with a detour, but it’ll come back in the end. Suppose, for instance, you wanted to do face recognition. You are given a bundle of face images. Each image contains pixels, and each pixel has a brightness.
We could try to recognize faces by looking at the pixel similarity. But it isn’t very good. Faces will have a lot of things in common, and this commonality provides a great deal of noise. You would also have to work with the full image which contains a lot of data, so it wouldn’t be efficient to search through all the pixel information. A far better way of approaching the problem is to track characteristics of a face: distance between the eyes, nose shape, width of the mouth, jaw structure, and so on. If we transform the original images into this kind of data, we can throw away the pixel information and just use the facial characteristics instead.
One mathematical hammer which is able to this is the Singular Value Decomposition (SVD). SVD analyses the original images for what is common and what is varying. Then it reframes the images, describing them by their variances and commonalities. If we keep the parts that varies, but throw away the common stuff, we’ve achieved a way of compressing information in our images down to the parts which matter. These parts will largely coincide with characteristics of faces. This allows us to recognize faces much faster by comparing the variances found by SVD.
Likewise, if we take a lot of dungeon runs, we could look at which specs they contain directly. But a far better way is to use SVD. This reframes the runs, and SVD will find what is common between runs, and what varies. We’ll find the characteristics of compositions. By studying the most varying parts of our data, and throwing away all the common stuff, we can figure out the meta. SVD will compress the information down to something which can be understood much quicker, and give some hints to what might be going on.
10.3 Data import
We need access to the dungeon data, so we load it in:
Code
source('load-pairings.R')
10.4 Correspondence Analysis
10.4.1 Overview
If we look at all healers, there’s a distribution of them. You might be more likely to run a dungeon with a Druid or Shaman healer rather than a Monk healer, because some classes tend to be more popular than others.
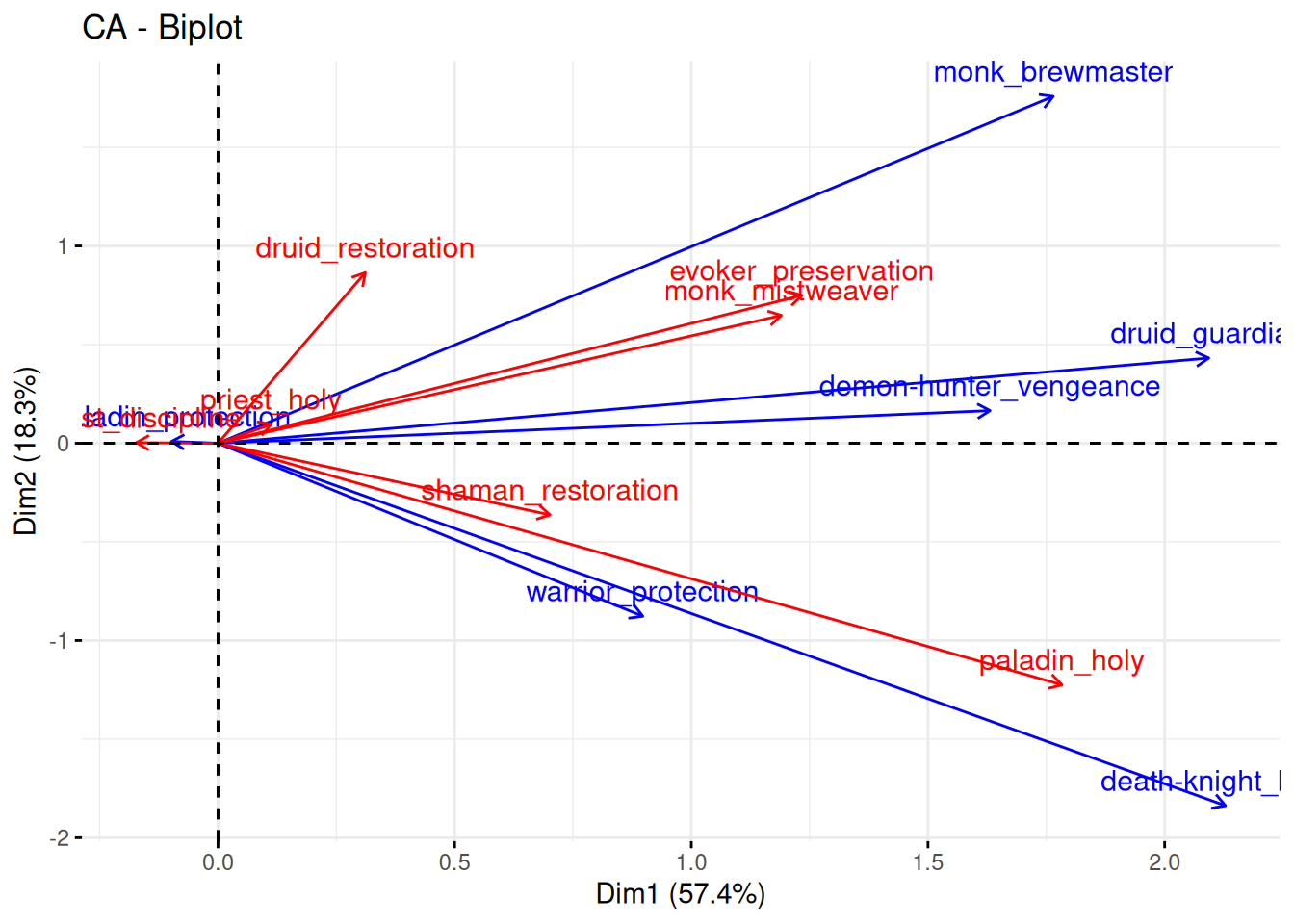
Now, if there were independence between healers and tanks, we would expect all tanks to have a distribution which tends to look like the grand distribution for healers. But if some tanks were dependent on some healers, we would see a different picture when considering that tank. A good example is a double-pairing. If you have a Protection Paladin in your group, you generally don’t see a Holy Paladin as the healer because you already get the Paladin-utility from the tank. Another example is that Brewmaster pairs well with Restoration druid because the healing-over-time of the druid interacts well with the stagger-mechanic on the Brewmaster. Stagger turns damage bursts into a damage-over-time effect, which is easily countered by the druid heal-over-time profile.
We can also view this dually, from the perspective of healers. Tanks have a general probability distribution, and were there independence, all healers would tend to play with that distribution. That’s generally not the case, however. Some healers enjoy certain tank pairings more than others. Restoration Druids wants to pair with Brewmasters for instance.
In essence, we can analyze both healers and tanks at the same time, and the necessary math computations agree at the optimal point1.
1 In math, this concept is known as duality and it is fairly common. By solving either side of the duality, you automatically solve the other side as well. This allows you to approach the problem from multiple directions at the same time.
What Correspondence Analysis does, is to figure out where there are differences from the grand probability distribution. And it points toward them, so you don’t have to stare for long at a table.
10.4.2 Dimensionality Reduction
Our main methods for visualization relies on dimensionality reduction. The data we have can be realized as a point-cloud in a high dimensional space. These spaces have very high dimensionality, 5 or more is common. We use a technique of dimensionality reduction to reduce the space down to 2 dimensions, so they can be plotted.
As an example, suppose you are trying to shoot a photo. The world is 3-dimensional, but the image which comes out of the camera is in 2d. In turn, the camera dimensionality reduces the world from 3d to 2d. When you take the shot, you are trying to line up a really good angle so the image looks awesome. You are optimizing the final image by moving the camera in the world such that it captures all the important stuff in a great way, and ignores the stuff you don’t care about. We throw away depth-information, but retain enough information that our brains can understand what the image depicts.
Our algorithm proceeds by setting up an initial world. Then it uses SVD to compute a new world in which we are describing the same data, but via the variances and commonalities of the data. In this new description of the data, we reduce it’s dimensionality to the dimensions which carry the most variance.
10.4.3 Contingency tables
CA works with contingency tables. This is a table with rows and columns. We let the rows represent tanks, so each row corresponds to a certain tank. The columns represents healers, and each column is a particular healer. A row/column pair (cell) contains a count, which is how many times we’ve seen that particular pairing.
Code
pair_tbl <-table(pairings_topk)
We can perform a Chi-square test to see if there’s independence between the rows and columns:
Code
X <-chisq.test(pair_tbl)
Warning in chisq.test(pair_tbl): Chi-squared approximation may be incorrect
When the P-value is low, independence is rejected. We can turn to CA in order to analyze where the dependencies are.
Code
res.ca <-CA(pair_tbl, graph=FALSE)
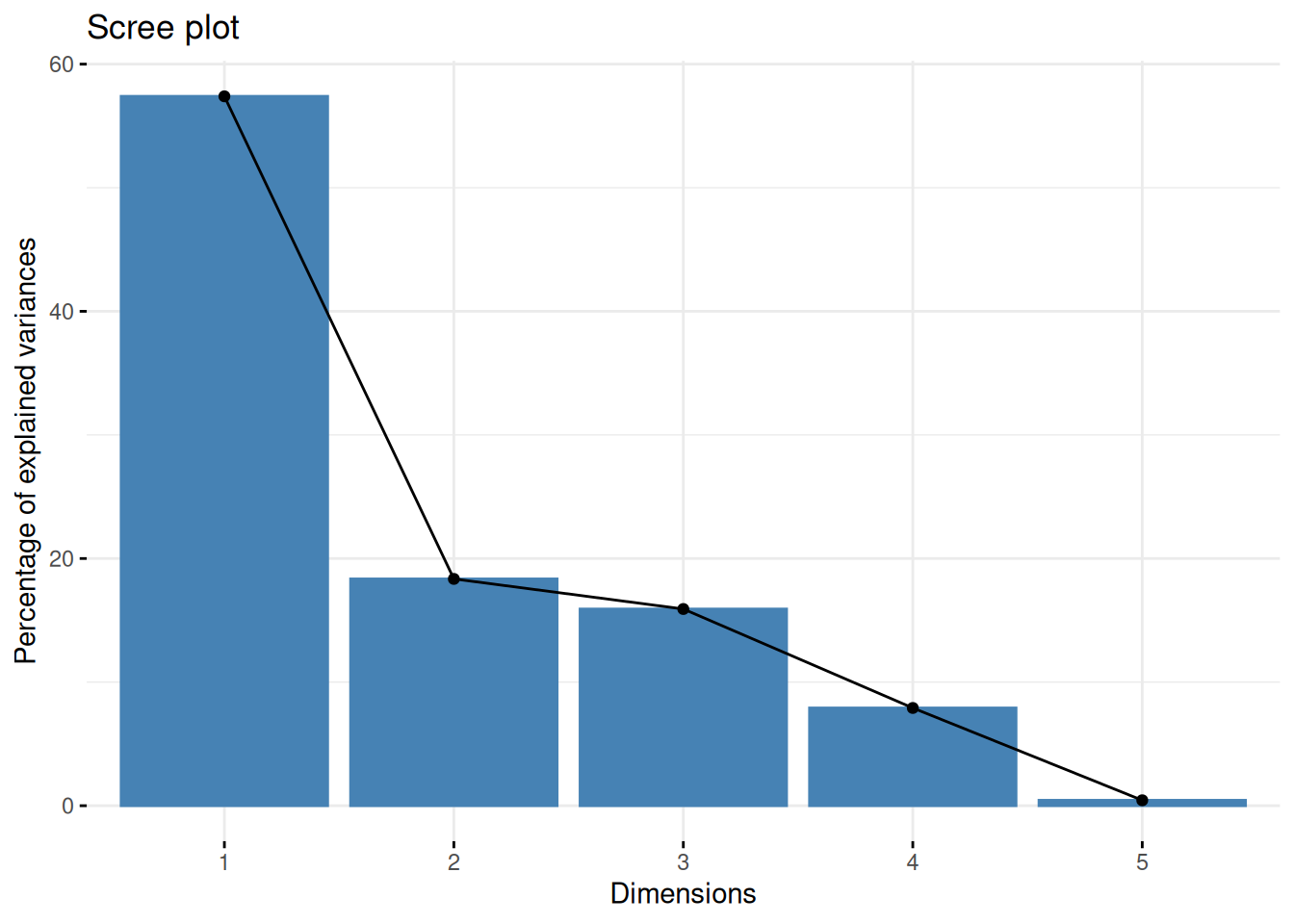
CA uses SVD to find a new frame of reference, and order the dimensions in order of their influence. We can plot the influence of each dimension in the new frame of reference:
Code
fviz_screeplot(res.ca)
This is a screeplot. It shows us that looking at the first two dimensions captures the majority of the variance in the data set. This allows us to plot those two dimensions as a 2d-plot:
The goal of this plot is to find similarities and differences between tank/healer parirings.
If a healer or tank is close to the center, it doesn’t have much influence.
If you analyze within the category of either healers or tanks, the distance between the specs matter. If, for instance, discipline-priest and mistweaver-monk are close, it means they are similar.
If you analyze between the categories of healers and tanks, the angle between the arrows matter. If the angle is small, there is a high similarity, even if the length of the arrow isn’t the same. At 90 degrees, there’s no similarity, and at 180 degrees, there’s anti-similarity. A typical opposition is protection-paladin and holy-paladin. If you already have one paladin in the group, you aren’t likely to add a 2nd one.
10.5 Multiple Correspondence Analysis
Correspondence Analysis works when you have two categorical variables, in our case Tanks and Healers. But if you have more than two categorical variables, CA won’t work unless you somehow transform your data. Another method, Multiple Correspondence Analysis (MCA) allows us to work with more than two categorical variables.
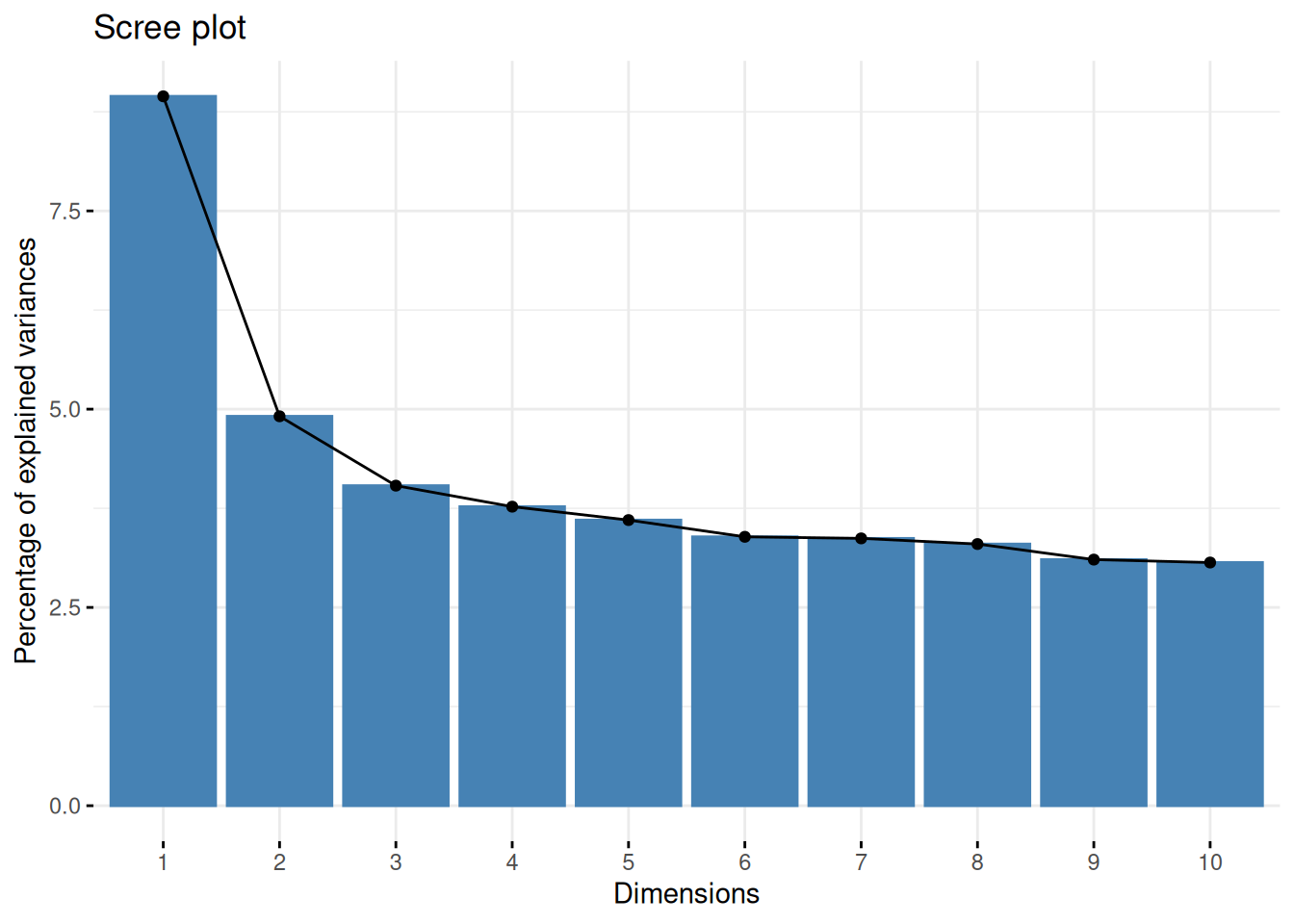
MCA is weaker than CA in the sense it tends to be less explanatory. In CA, it’s often the case our biplot can explain a lot about the data, more than 85% is not unheard of. In MCA however, the explanatory power will be greatly reduced. This is because more pairings are formed, so the space is way more complex and as a result, we don’t get the same explanatory power. In turn, we can’t find a single few dimensions (via SVD) which contributes most of the variance.
We still want to use MCA, because it allows us to get DPS classes into the mix. DPS classes are important because they can provide some crucial utility for dungeon runs. An example is the bloodlust effect. If you don’t employ a healer with bloodlust, you are likely to want it on a DPS. Another example would be Druid’s “Trees” (In Shadowlands), or priests “Mass Dispel” ability.
A team will (typically) have 1 tank, 1 healer, and 3 dps2. The order in which the DPS occur in a list don’t matter. If we have [Shadow Priest, Balance Druid, Enhancement Shaman] it is the same as if we had any other permutation, for instance [Balance Druid, Enhancement Shaman, Shadow Priest]. We’ll have to capture this fact somehow, so we can’t just build a table with columns [Tank, Healer, DPS1, DPS2, DPS3].
2 The exception are no-healer shenanigans
This leads to the idea of having a large table. Each row is a run. There’s one column for the tank, and one column for the healer. There are numerous columns for the DPS, one for each. They contain a Yes/No depending on the presence or absence of that particular DPS in the group. This won’t capture having multiple copies of the same DPS, but this is fairly rare at the high level. Usually you tend to get the utility from the first specialization and will seek other specializations for remaining spots.
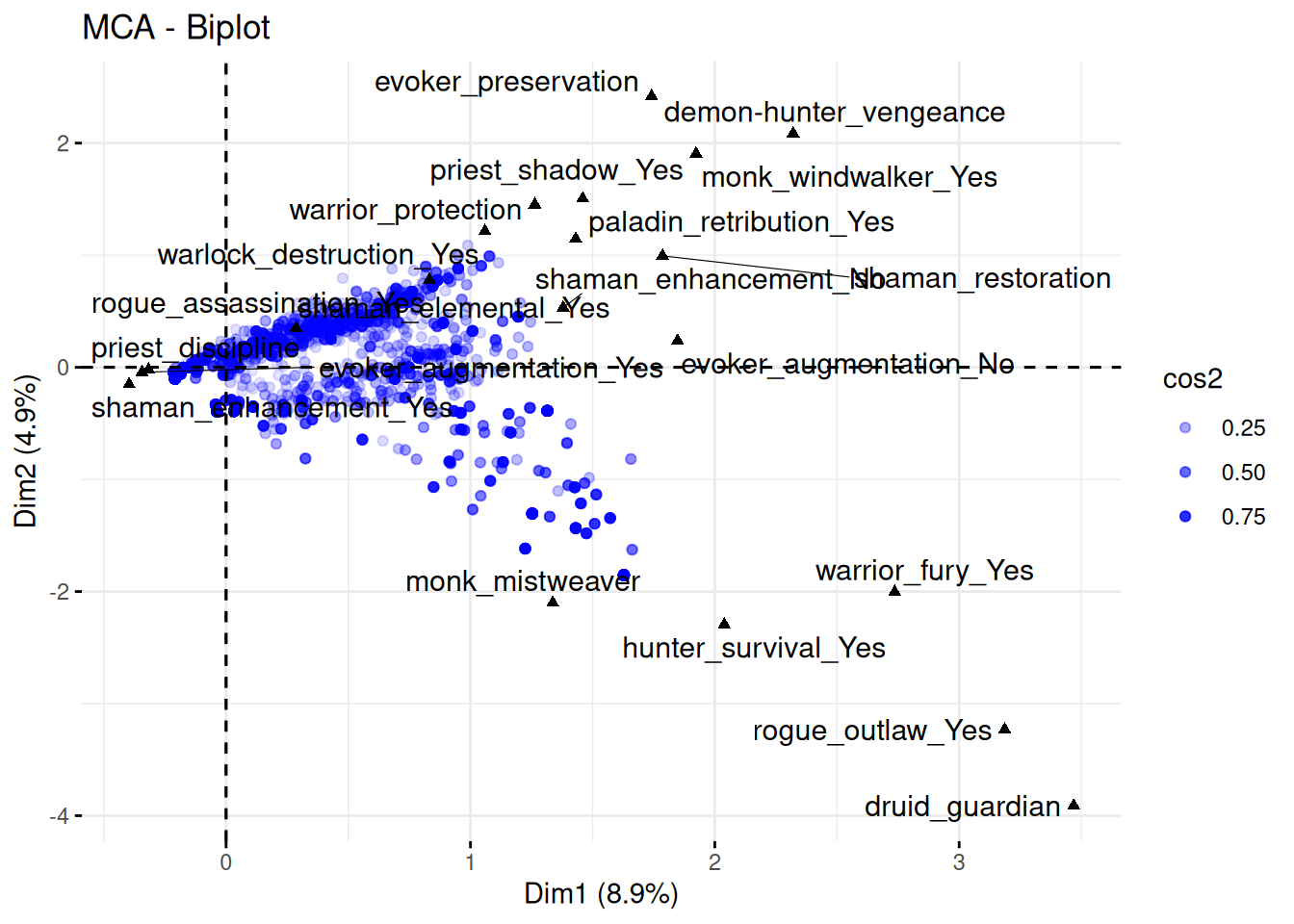
In the biplot, each dot is a run, projected onto our plane of maximal variance, as found by MCA. Each triangle is a variable. Tanks and healers have a category each, whereas we have two for each DPS: Yes and No. We only select the 20 most influential variables.
When interpreting biplots, one should look mostly at the variables (triangles). Variables which are close in distance have some similarity in the data. If, for instance, priest-discipline, priest-holy, and priest-shadow_No are close, it means that you are running a priest. Either as a shadow priest, or in the case you don’t have one, a healer priest.
Furthermore, the variables far away from the center of (0,0) are more influential in the sense they are defining what the compositional clusters look like. Variables in the same direction are related. Variables in opposition to each other are negatively related.
If, for instance mage_fire_Yes and druid_balance_Yes are opposed to each other around (0,0), then they are related negatively: if you have a fire mage, you are less likely to also have a balance druid.
One reason for such an opposition requires some extra thought. For the example above, which is taken from Season 2 of Dragonflight, we have a Shadow Priest in almost every group. If you then pick both a fire mage and a balance druid for the group, you end up with no melee DPS. This means the group will have to seek its interrupts on the tank and healer, which limits which tanks and healers are possible.