This chapter addresses some of the weaknesses in the data set, comparing corrections to the base level used by Subcreation. Each subpart here addresses a specific shortcoming.
6.1 Using the full sample
One thing I don’t particularly like about the data analysis is restriction to the top 100 runs. it will ignore the more difficult dungeons, which we collected via stratified sampling. We can ask what happens if we just compute a confidence interval on the full sample, in the traditional way. This avoids all the broken computations which blends data from the top-100 and the full sample.
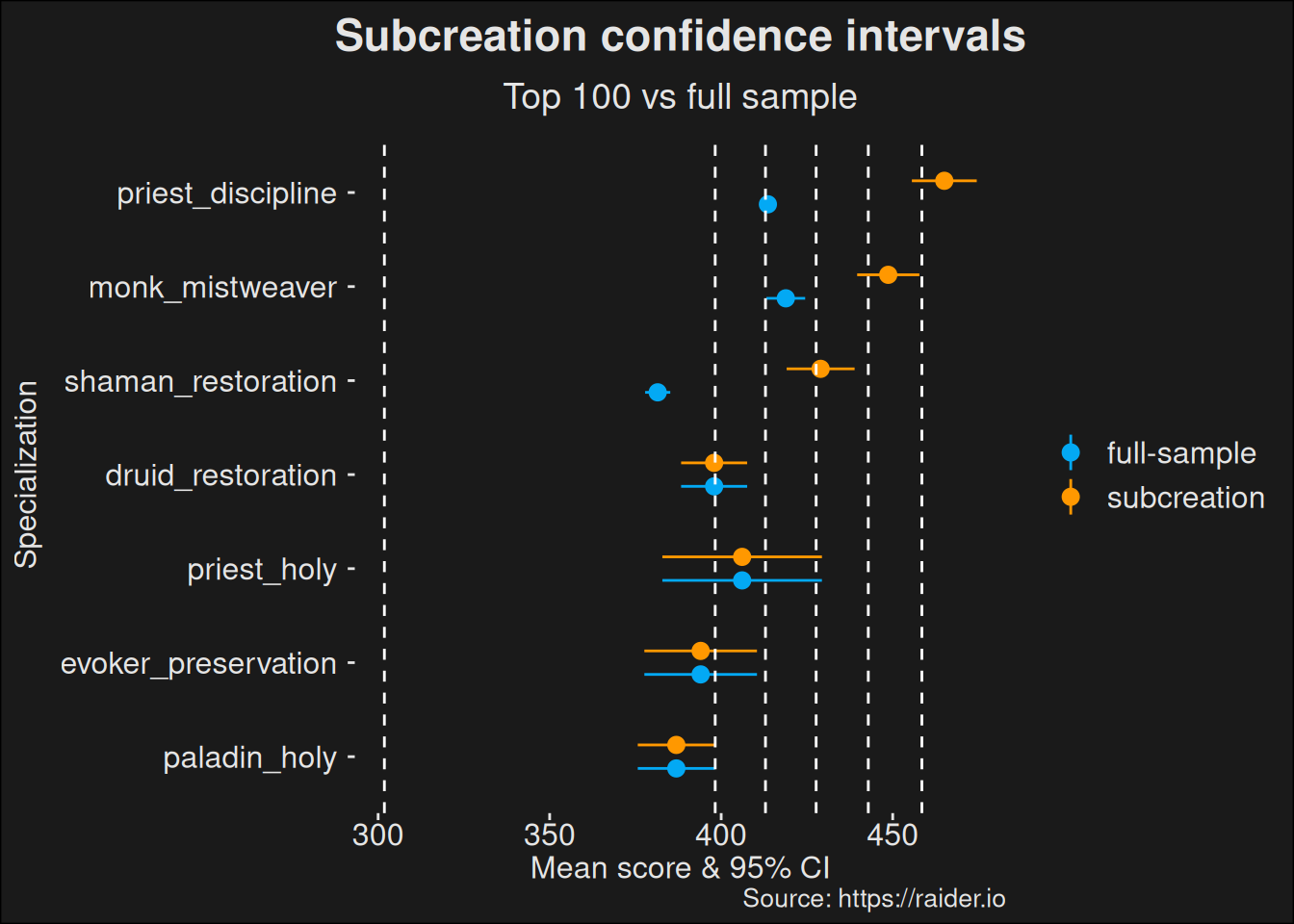
The way we’ve set up data frames with an analysis tag will let us compare the difference between the two ways of computation. Here we use colors to differentiate between the methods used by Subcreation, and using the full sample. Note how the popular specs are beeing reeled in. This is to be expected, because when we don’t pick the top-100 for those specializations, we are not selecting the best runs among the higher population count.
Some players are likely to be better than the average of our selected runs, and some are likely to be worse. Subcreation just picks all the lucky dice throws, and ignores all the unlucky ones. I’m arguing this is a bad practice, because the popular specs get far more dice throws than the less popular specs.
Figure 6.1: Plot where we compare the original Subcreation model (top-100 runs) to the full sample data where all runs are included. The intent is to show there’s a difference based on what model you decide to use. How you decide to handle your data can have a large effect on the outcome and also the conclusion people will end up making based on the data.
6.2 Regional Effects
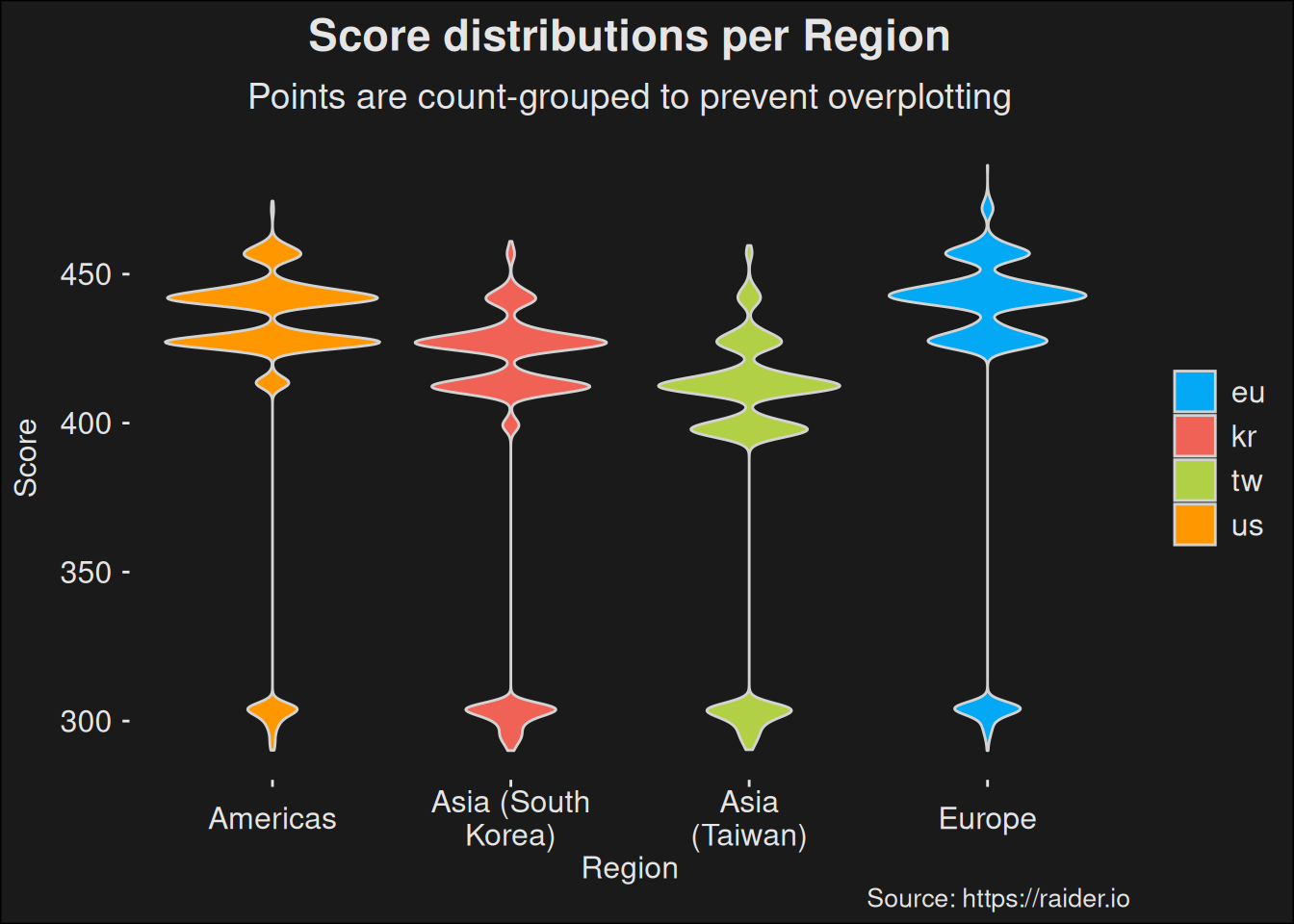
The choice of stratifying by region ensures we are getting a share of runs from every region. But because we are also purposively sampling the top players, it is important to ask if there are any regional differences. We can do that via a quick violin-plot over all the data, but split by region.
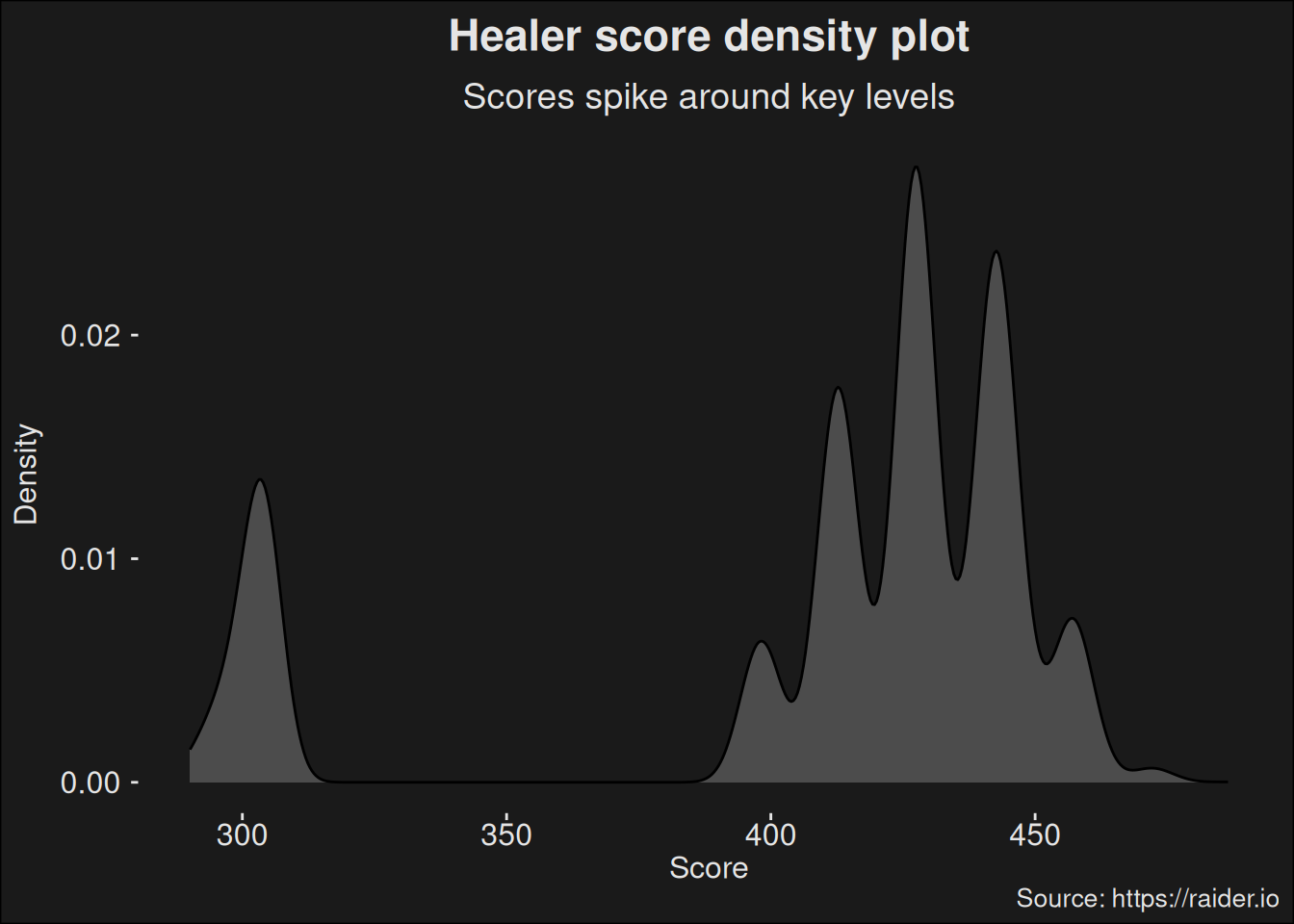
Violin-plots are in the family of density plots. In statistics a density (Probability Density Function / PDF) tells us the relative likelihood of drawing a value from the distribution. Where the distribution has mass, there is a larger likelihood of getting a value. In the violin-plot, we can see that scores are more likely to be around certain threshold values. These correspond to key-level increases. The variance within a given key level pertains to the clock and how much time was left on it. In “between” key levels, there are no observations at all, so the density violin becomes very thin.
Code
ggplot(specs, aes(x = region.str, y = score, fill=region)) +geom_violin(color="lightgray") +labs(title ="Score distributions per Region",subtitle ="Points are count-grouped to prevent overplotting",caption ="Source: https://raider.io",x ="Region",y ="Score") +scale_fill_material_d(palette ="light") +scale_x_discrete(label = scales::label_wrap(12))
Figure 6.2: Score distributions split by region shows regional differences.
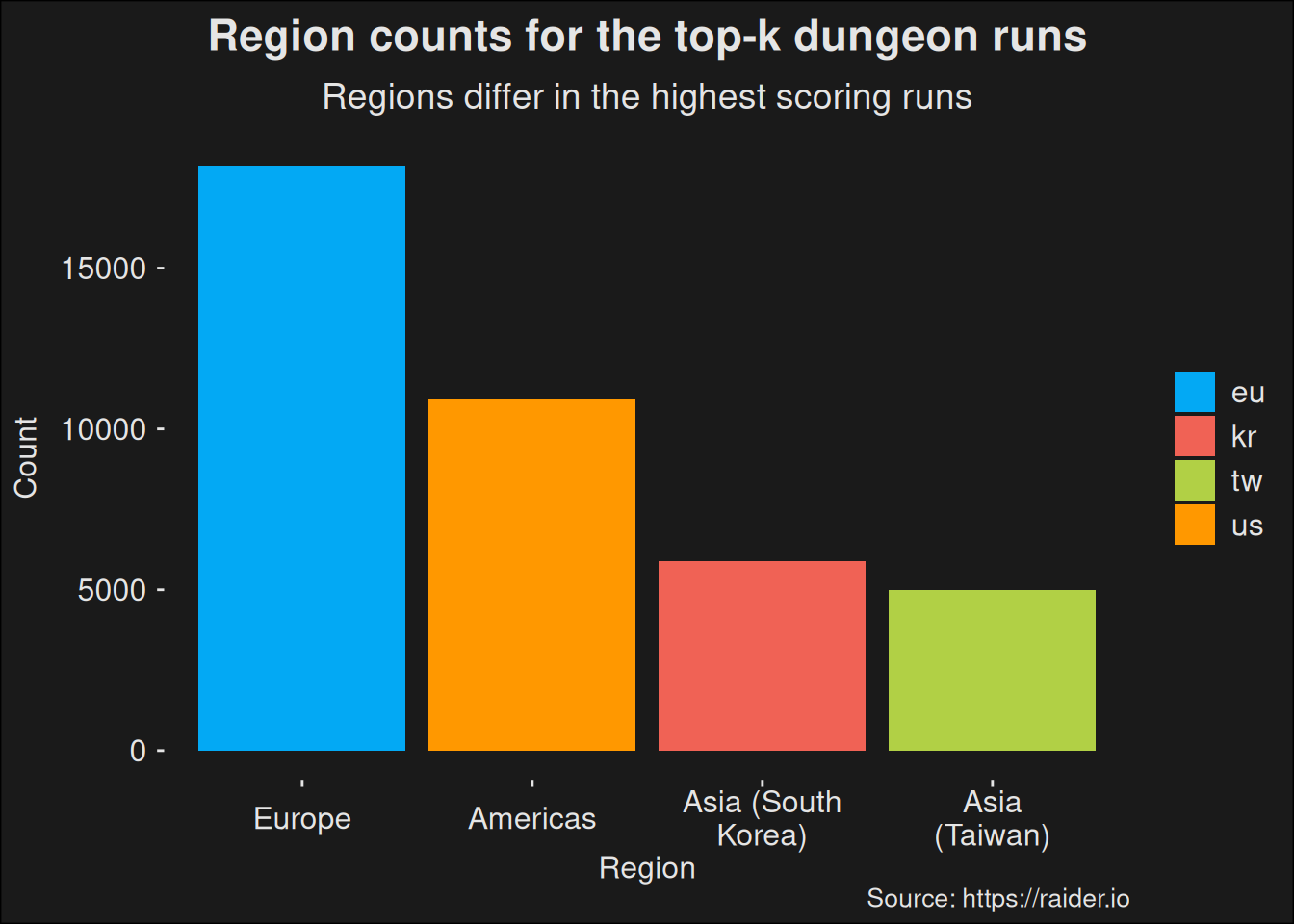
We see there are considerable effects from regional differences. Data from Asia are likely to have an effect on our results. In particular, we aren’t measuring the top players. It is very likely if we just pulled more data from the Europe and Americas regions, we would see a real view of the top players. The data set we are working with have the following regional counts
Figure 6.3: Table counting the number of runs per region in the base data set.
But we also have an alternative data set, where we find the world-wide top dungeon runs for the week. This dataset is called specs_topk. This data set have counts which differ:
It is worth stressing the regional difference is largely due to population counts. The regions with a lot of players will be able to push key levels quicker because there are more players running those keys. Hence, it is far easier to form groups. Also, because we are sampling among the top, a larger population in a region means we’ll have more skilled players in the region, even if we assume no skill difference.
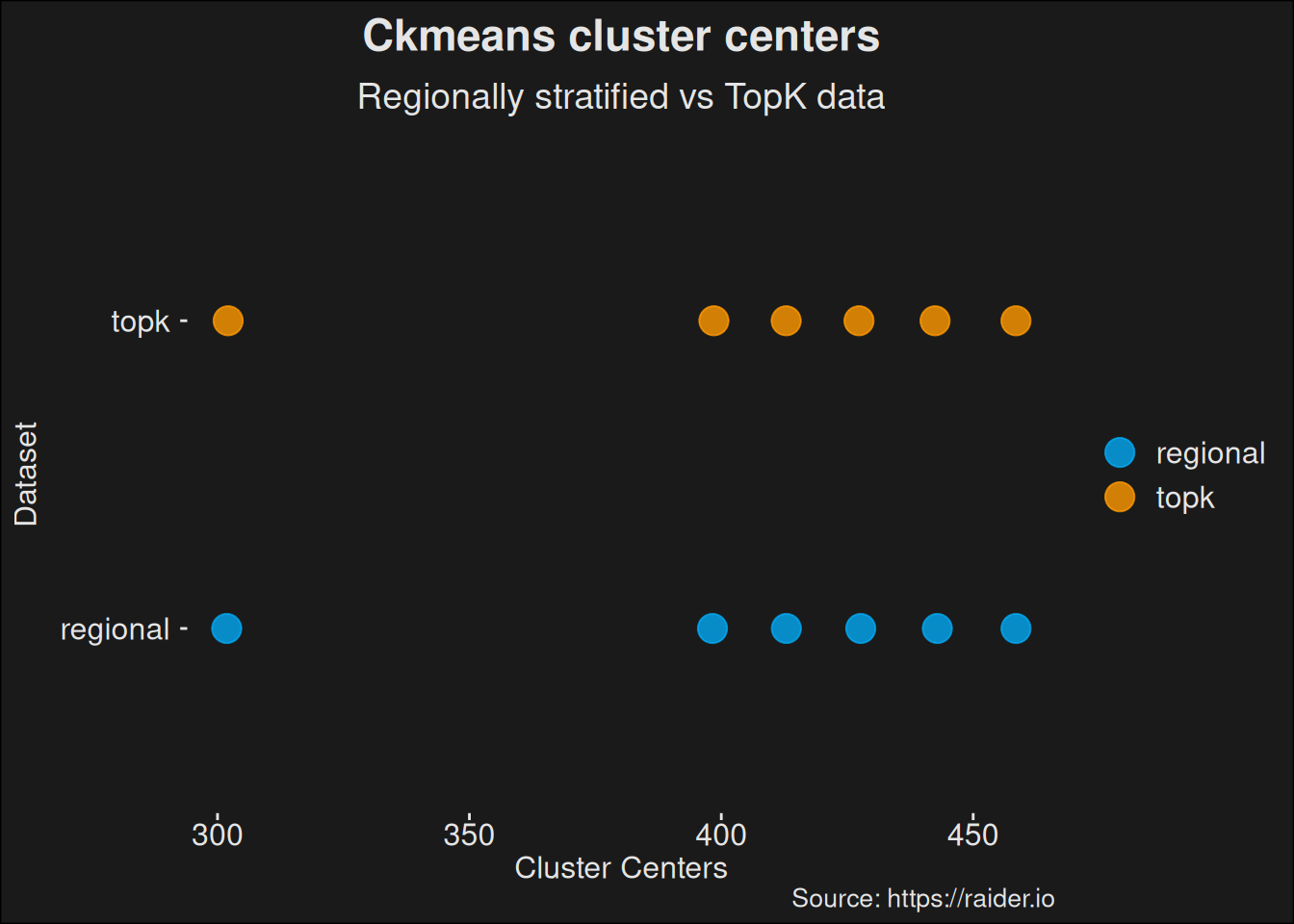
Figure 6.4: Plot comparing clusters computed on the original Subcreation sampling scheme and a top-k sampling scheme. This shows how the clusters move when we change the underlying data set.
We can repeat the same computation Subcreation uses, but on this new data set.
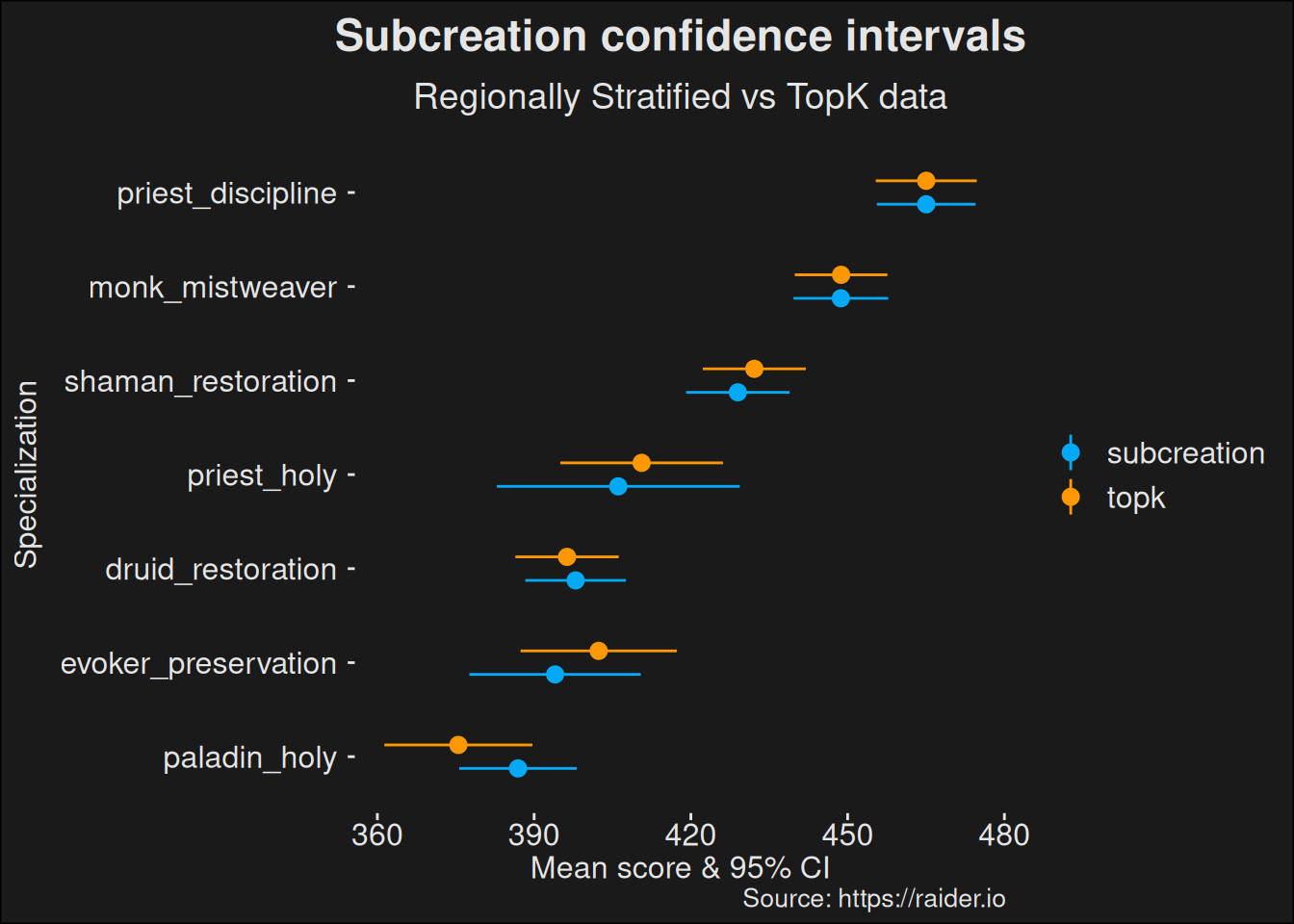
Running the comparison shows us a major change among the unpopular specs. Remember, in subcreations computation, you pick among the best 100 runs for each healer, but for the unpopular specs, there aren’t even 100 runs. So you pick all of them. If you stratify over region in your data collection, you will get more players from the Asia regions, which runs lower key levels in general, skewing the results.
Figure 6.5: Compare the Subcreation base computation with a dataset where the top players are picked world-wide rather than being stratified per region. The plot shows how computing data among the true top-k players alters the outcome of the analysis.
6.3 Controlling for repeated measures
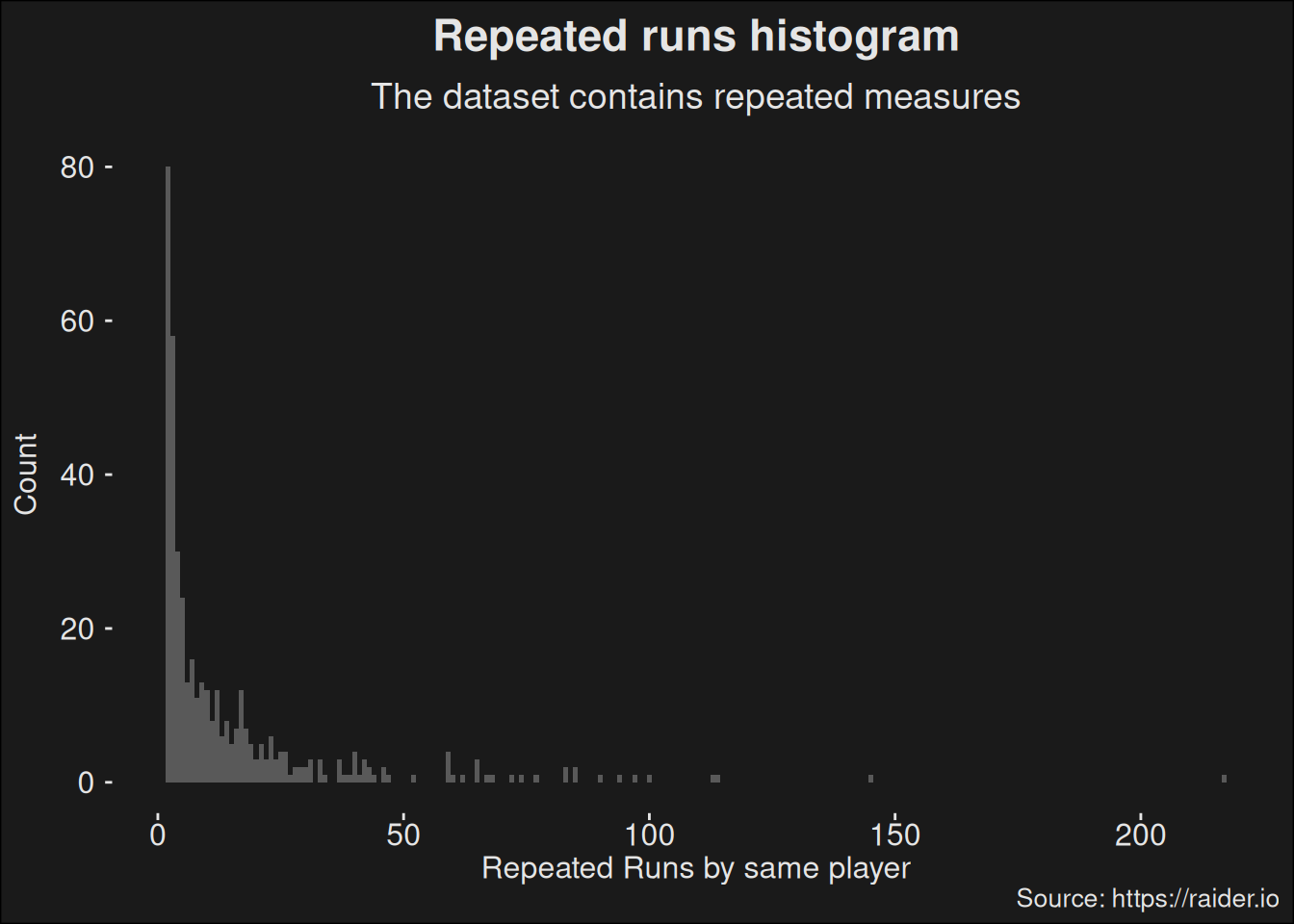
Statistical work often have assumptions which have to be fulfilled for the math to work out as expected. Violating the assumptions voids the correctness of the statistic. One such assumption is independence; each observation is independent of other observations. If you have 7 Protection Paladin runs in Shadowmoon Burial Grounds, the assumption is that those runs are done by 7 different Paladins. If all those 7 runs were done by the same player, it would be wrong to count this as 7 independent samples.
We can analyze the data set for repetitions by grouping on the unique Id of players.
So a lot of runs repeats, and it is very likely to affect our results. This is something you have to control for when handling the data. As an example, we can look at specialization-popularity but control for repetitions in the data set:
`summarise()` has grouped output by 'class', 'class_spec'. You can override
using the `.groups` argument.
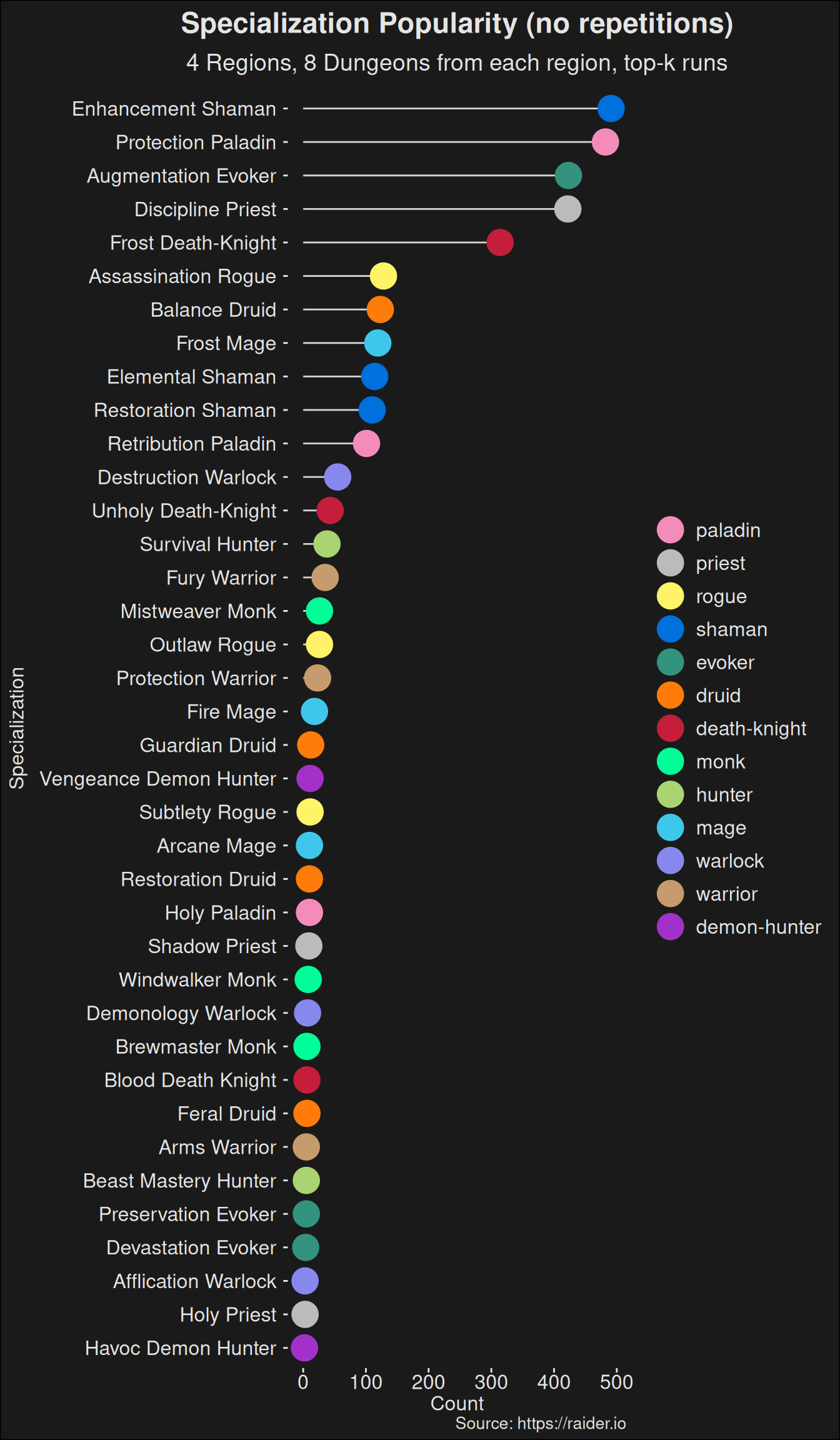
Figure 6.6: Counting the number of specializations with no repetitions of players. This avoids the pseudoreplication which is present if you just naively count specializations as we did earlier.
Compared to the uncorrected plot, it’s fairly obvious active players have an effect on the outcome. Active players will do more runs, and that leads to a conclusion there are more players at the top level playing a given specialization. The plot in Figure 6.6 is a more accurate way of looking at popularity among specializations.
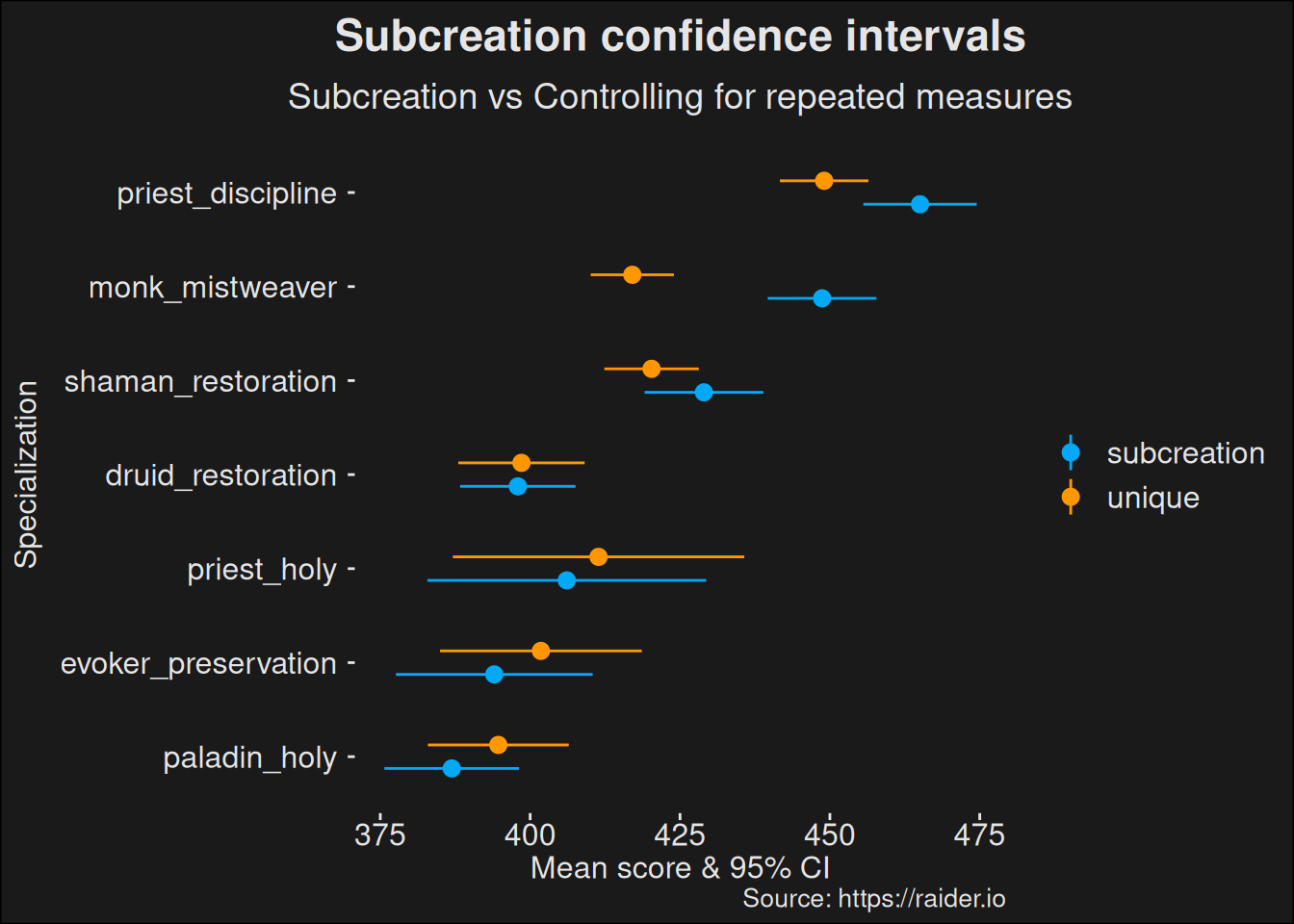
We want to keep individual dungeon runs separated. That is, if a player has run different dungeons, we are assuming they are independent runs. Because we might have dungeon runs at several different key levels and with different times remaining, we remove duplicates. A more advanced model would take the dungeon variability into account as well, but this will do for now.
We see yet another correction has influence in the reported mean values. The general trend is an adjustment downwards, because we don’t let a single healer influence the numbers too much. Some of the more popular specs are heavily influenced by single players who play the spec a lot, which means the skill of a few individual players have a large effect on the perceived power of the specialization.
A core assumption of Subcreation is that the data follows a normal distribution. If the data isn’t normally distributed, chances are this assumption is violated, and the statistics become weak.
Code
ggdensity(healers, x ="score", fill ="grey50", ggtheme =theme_zugzug()) +labs(title ="Healer score density plot",subtitle ="Scores spike around key levels",caption ="Source: https://raider.io",x ="Score",y ="Density")
Kernel density plot of the healer scores.
We know this dataset isn’t normally distributed. Mythic+ scores are artifically generated by combining key level, affixes, and time remaining in the dungeon. Since the base score for each key level has gaps in between them, our data set has gaps as well. There are certain scores which are unobtainable in between key levels, which violates the assumption the data is normally distributed. We can analyze the data via a Shapiro-Wilk test. This test sets up a hypothesis that the data is normally distributed; then asks “Assuming data are normally distributed, how likely is the data we have?”
If this test comes out with \(p < 0.05\) this data would occur at random less than 5% of the time.
Code
healers |>slice_max(score, n =4000) |>summarize(shapiro.p =tidy(shapiro.test(score))$p.value) |>kbl(digits =3) |>kable_styling()
shapiro.p
0
This value is practically 0, so it fails the test.
A way around this conundrum is to use bootstrapping. We can let a computer grind at the problem by resampling our population and derive a 95% Confidence interval from the resampling. This will then estimate the confidence interval1. A bootstrapped approximation puts us on saner statistical ground than the current computation.
1 This is due to the resampling forming a sampling distribution, which means we can invoke the Central Limit Theorem.
Code
confidence_interval <-function(data) { mean <-mean(data$score) sd <-sd(data$score) n <-length(data$score) error <-qt(.975, n-1) * sd /sqrt(n) conf.low <- mean - error conf.high <- mean + errorc(conf.low, conf.high)}confidence_interval(healers |>slice_max(n =100, order_by = score))
[1] 463.7793 466.2324
Bootstrapping works by sampling in the sampled scores with replacement2. We create a “new” sample of 100 healers via this resampling, and then we take the mean. This process repeats. If we keep creating “new” samples this way 5000 times, we have 5000 means. These are a sampling distribution, and we can then compute the 95% confidence interval on that distribution.
2Replacement is a fancy way of saying we can pick the same sample more than once.
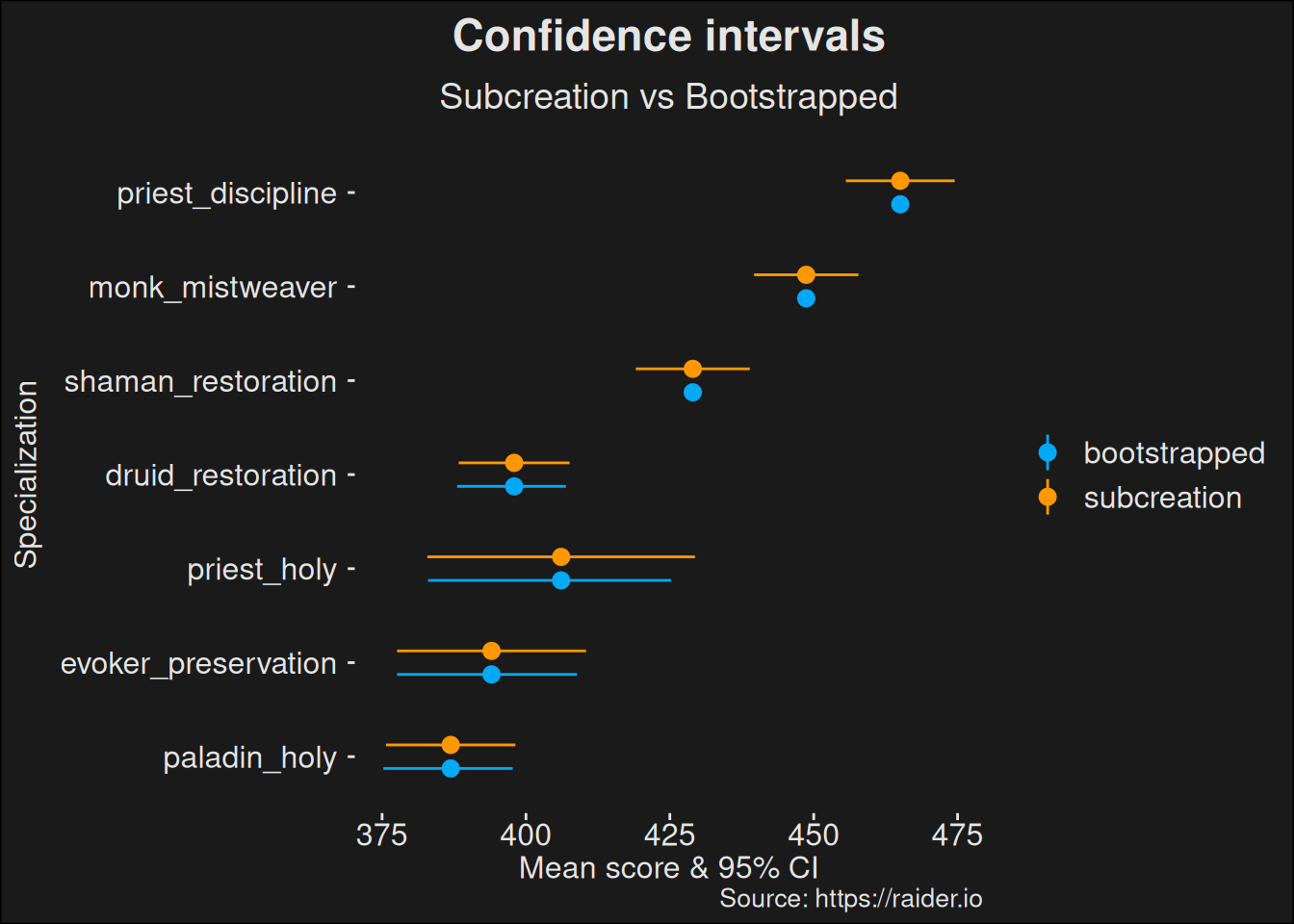
Let us compare the bootstrap to the original subcreation computation. We can plot this, which is a better way of understanding the differences, than looking at a table.
Figure 6.7: Bootstrapped confidence intervals compared to the Subcreation base computation.
One advantage of this approach is that it is more robust against changes in the underlying data. We see the derived confidence intervals via bootstrapping tends to be smaller. If we want to analyze if specs are different, having smaller confidence intervals tend to be better because there will be less overlap of the intervals. Usually this will let us tease out smaller effects from the data.
6.5 Combining all the Alternatives
We have a number of alternative suggestions for Subcreation. These are:
Use the full sample
Control for regional effects by pulling a true topk dataset
Control for repeated measures from players
Bootstrap the confidence interval
Combining all these suggestions is an obvious idea, which should yield better results.
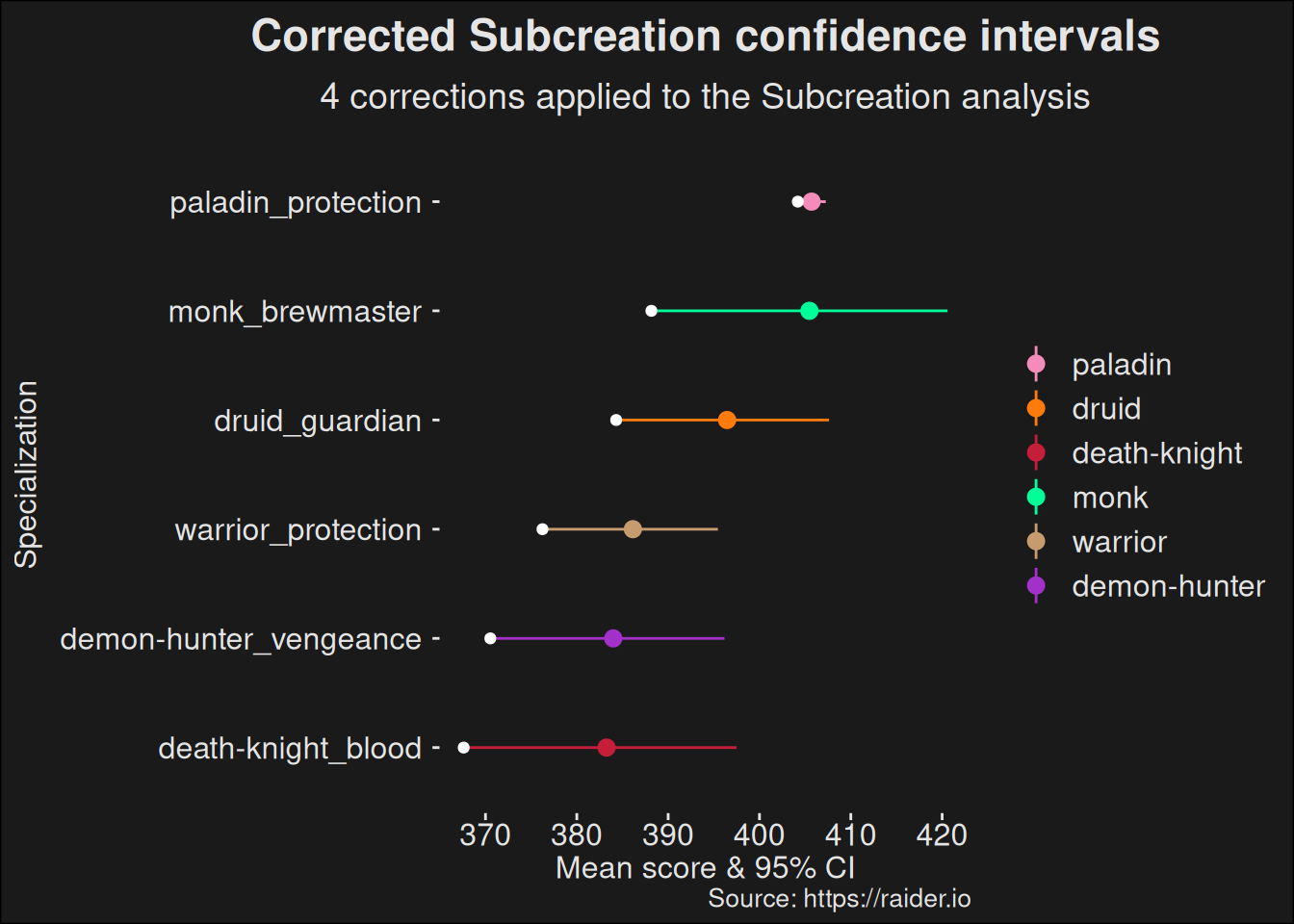
6.5.1 Healers
Because we want to run the computations for healers, tanks, and dps, we benefit from setting up a function for doing the computation. The function preprocess combines all our controls and runs them in order.
preprocess <-function(df, tag) {# Handle repeated measures by averaging players over their multiple runs of the same dungeon df <- df |> dplyr::group_by(dungeon, id) |> dplyr::reframe(class_spec = class_spec,dungeon = dungeon,class = class,name = name,mean_score =mean(score)) |>mutate(score = mean_score) |>distinct() |>ungroup()# Bootstrap a confidence interval df <- df |>group_by(class, class_spec) |>filter(n() >3) |>nest() |>mutate(bootres =map(data, run_boot)) |>mutate(tidy =map(bootres, broom::tidy, conf.int =TRUE)) |>unnest(tidy) |>mutate(data =NULL, bootres =NULL) |>ungroup()# rename columns to fit the rest of the data here df <- df |>rename(conf.low = conf.low,conf.high = conf.high,score_mean = statistic) |>mutate(analysis = tag) df}
With this function in hand, we can easily run the computation for different roles. We’ll focus on healers first.
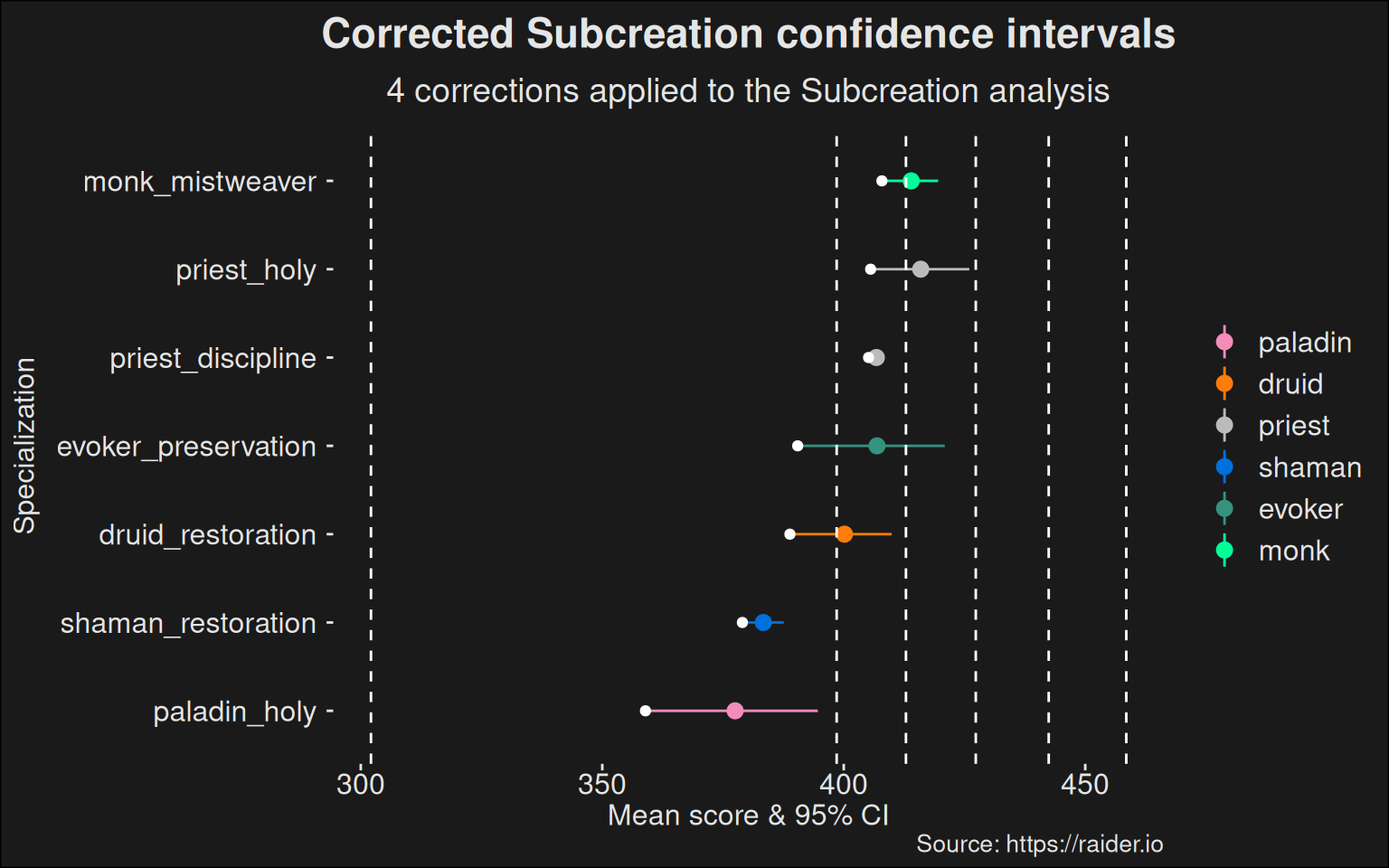
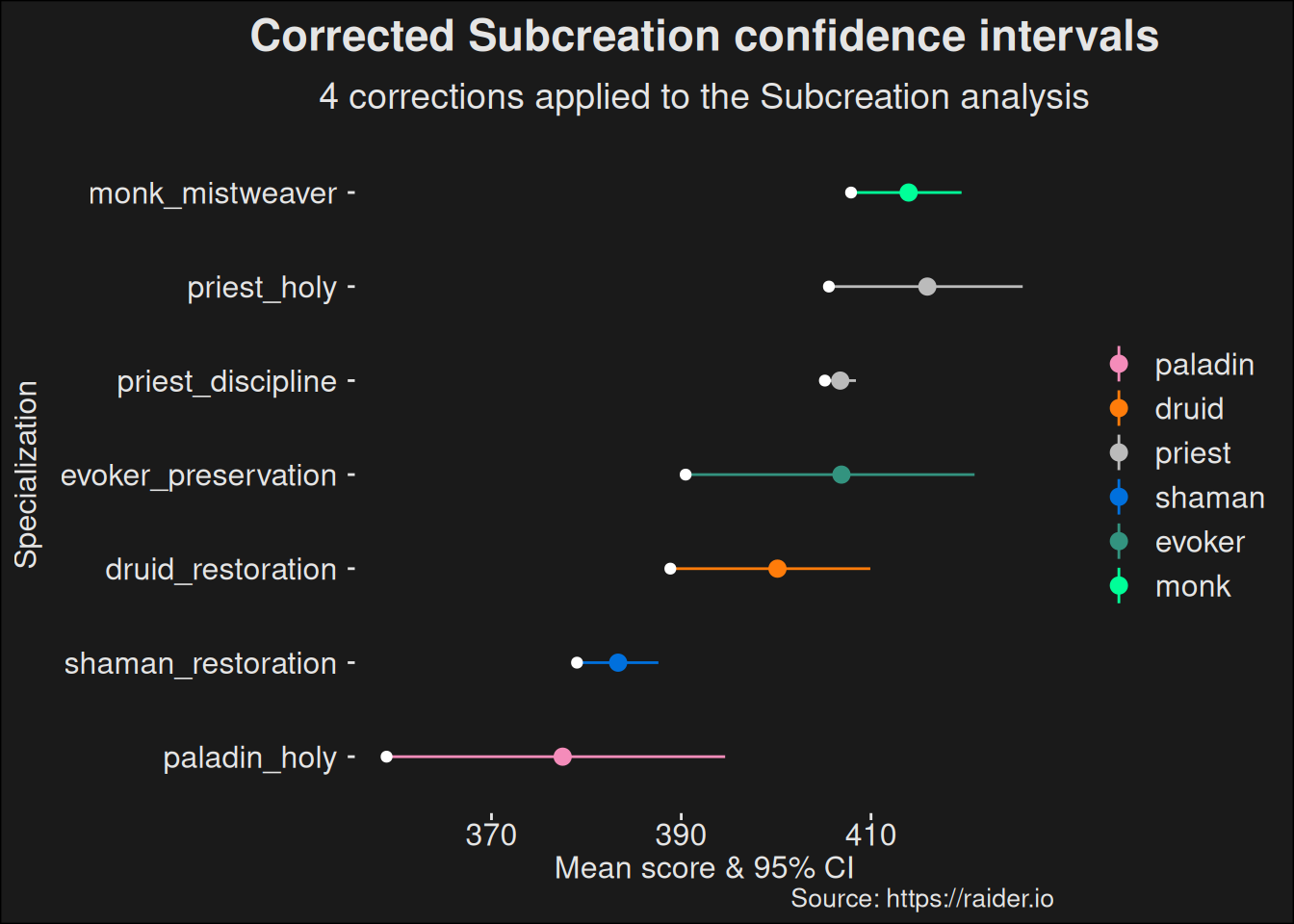
Once we control for undesired effects, it becomes clear the healers tend to be far more balanced. The difference in rating between the best and worst healer becomes far smaller. Because they are so close, we also provide a zoomed-in view with no clustering:
Note how much the distance between the best and worst specs have shrunk. The balance window closes. This means the difference in power is going to be a small effect, and other factors, such as player skill, are going to dominate. This is good for the game, as you’d like to pick better players than relying on specialization power to construct a roster for a dungeon run.
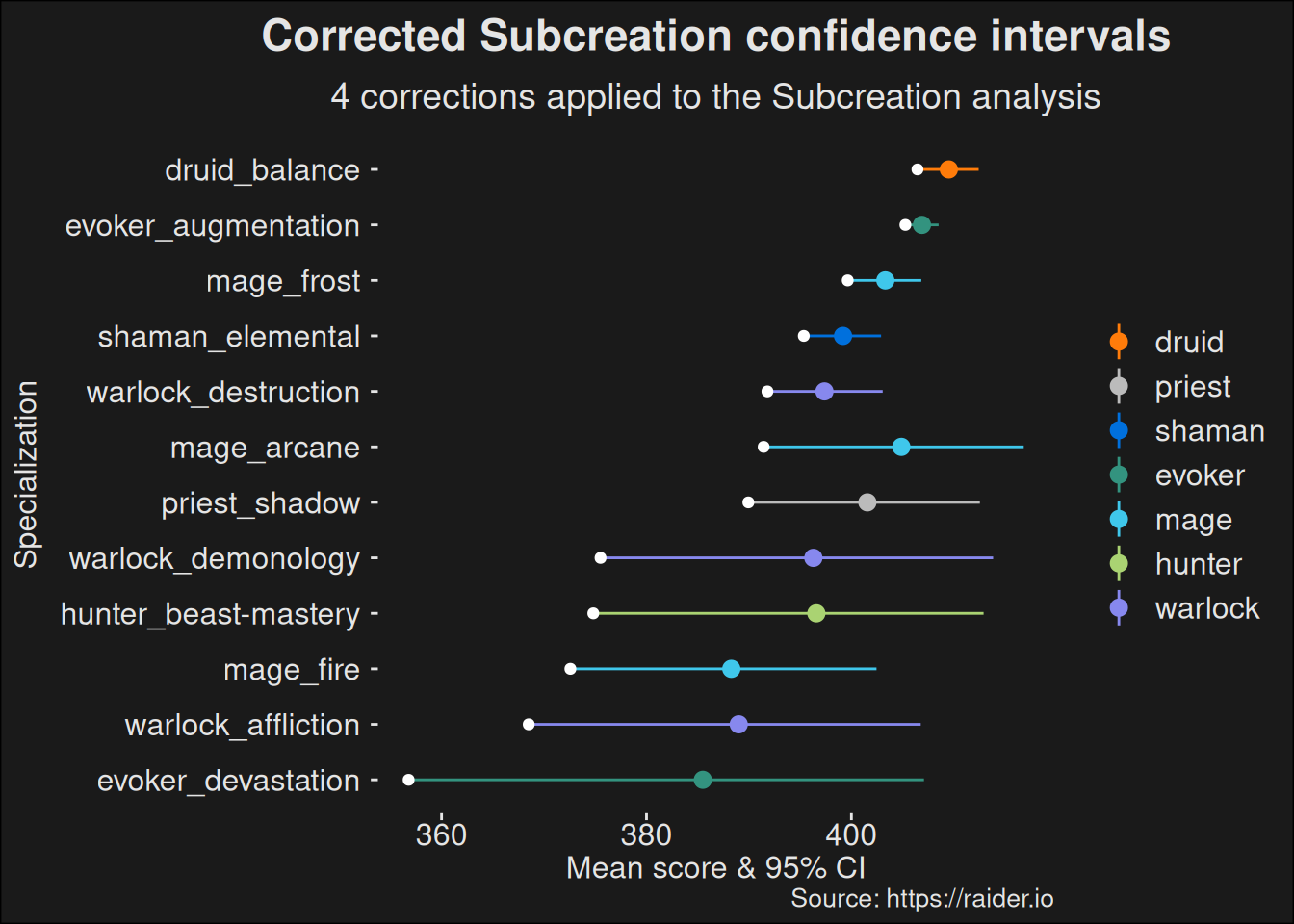
6.5.2 Tanks
With the preprocess function in hand, we can now focus on tanks:
Like in the previous work on healers, we don’t need the cluster centers anymore, so we’ll make a plot without those. This lets us focus on where the differences are and how large of a difference there is.
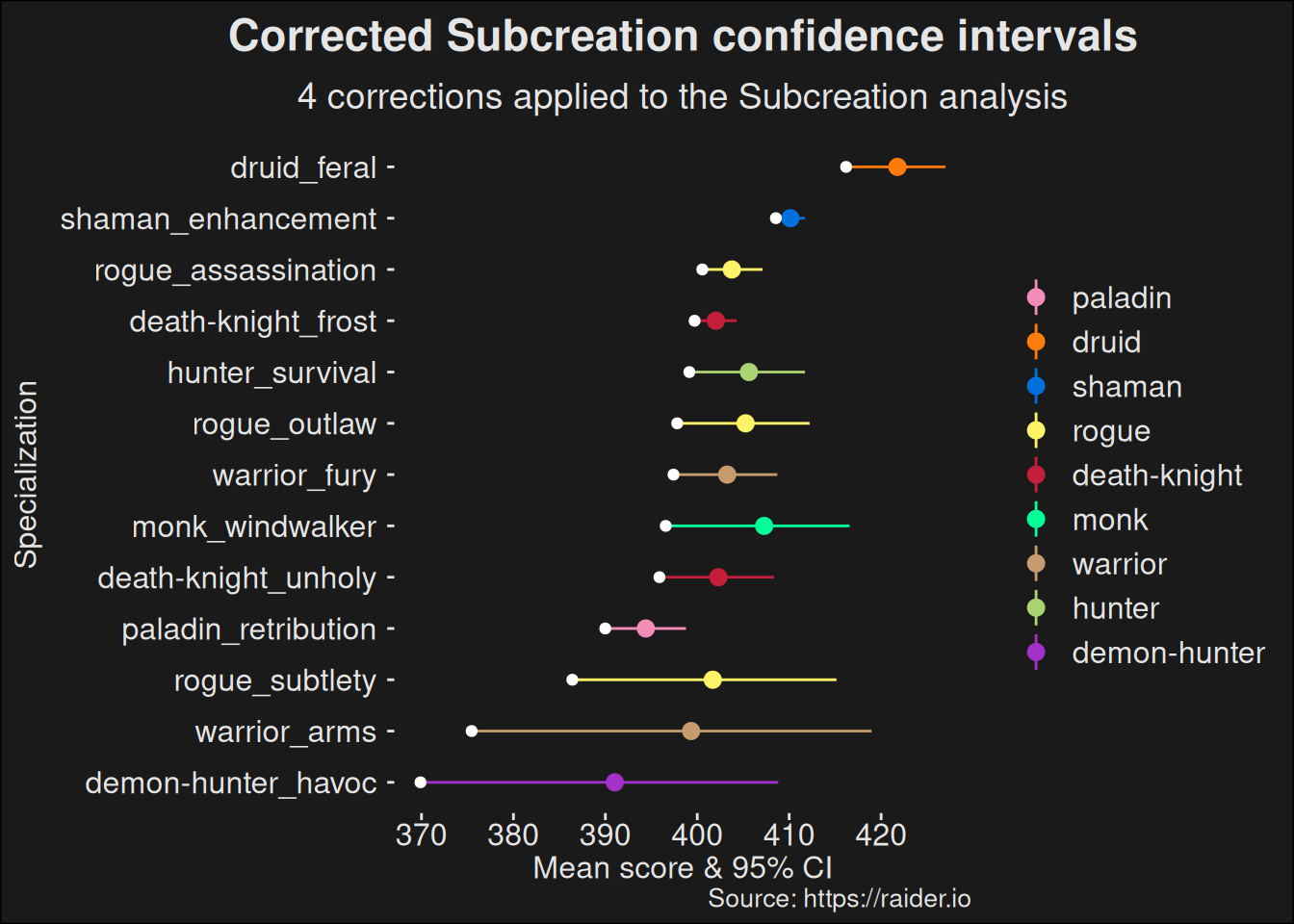
For convenience, we split the DPS role into ranged and melee. This keeps the plot in a size that is readily workable and easy. It is also common practice in a lot of data expositions about specializations in WoW to do so. We’ll just follow suit.
By now, the drill is known, so we’ll just bring the plots
We’ve traced the computations done by Subcreation and then provided a series of corrections to the computations. Before these corrections, the balance window reported by Subcreation is fairly large.
However, once you control for undesirable data effects, the balance window almost closes.
The findings here are presented one change at a time with a comparison, because it allows people to make their own informed decision on what they believe.
Should Subcreation want to implement some of this, they have the option. They can pick whatever they want among the options, including those they think are correct.
The key take-away is that something can be statistically significant, but have small effect. This is especially true if you have a lot of observations. The statistics can squeeze out significance, even for very minuscule differences among the specializations. I think this is what is happening here, and it is happening across all roles. Except for a few outliers, most specs fall into a very small window.
Some of the suggestions here are outright hacks3. By this, I mean they fix problems with the approach, but does so with a focus on being rather simple fixes to add to the Subcreation site. This is deliberate. I’d much rather see some of the suggestions here implemented, even if they are simple in nature. Other chapters address the specialization power question with a stronger toolbox from statistics: bayesian inference. This approach is arguably the correct one, but it also involves a lot more machinery, is computationally heavy, and requires one to work with a probalistic programming language such as stan.
3 Here a hack means overcoming an obstacle via non-traditional means